18. Limit Theorems and Monte Carlo Method#
Last Time#
Part I: Random Walk
The drunkard’s walk
Biased random walks
Treacherous fields
Part II: Stochastic Programs
The concept of random variables
Distributions
Today#
Introduction#
An Experiment#
Assuming \(X \sim Uniform(0,1)\), we would like to know the sample mean \(\bar{X} = \frac{X_1 + X_2 + \dots + X_n}{n}\) and its variance \(\text{Var}(\bar{X})\) under different value of \(n\)
import numpy as np
def test(a=0, b=1):
"""Uniform distribution"""
for numSamples in [1, 10, 100, 1000]:
sampleMeans = []
for i in range(100):
# Generate random samples
rng = np.random.default_rng()
samples = (b-a) * rng.random(numSamples) + a
sampleMeans.append(np.mean(samples))
print("Number of Sample = {}".format(numSamples))
print(" Theoretical: (Mean, Var) = ({:.2f}, {:.4f})".format((b+a)/2, (b-a)**2/12))
print(" Sample: (Mean, Var) = ({:.2f}, {:.4f})".format(np.mean(sampleMeans), np.var(sampleMeans)))
test()
Number of Sample = 1
Theoretical: (Mean, Var) = (0.50, 0.0833)
Sample: (Mean, Var) = (0.50, 0.0998)
Number of Sample = 10
Theoretical: (Mean, Var) = (0.50, 0.0833)
Sample: (Mean, Var) = (0.51, 0.0080)
Number of Sample = 100
Theoretical: (Mean, Var) = (0.50, 0.0833)
Sample: (Mean, Var) = (0.50, 0.0010)
Number of Sample = 1000
Theoretical: (Mean, Var) = (0.50, 0.0833)
Sample: (Mean, Var) = (0.50, 0.0001)
What have we learned in this simulation?
As the number of samples increases, the value of sample mean tempts to converge and its variance decreases.
We already know the truth that \(\mathbb{E}[X] = 0.5\) for \(X \sim Uniform(0, 1)\).
After this simulation, we can confirm that this is truth.
Pascal’s Problem#
Reputedly, Pascal’s interest in the field that came to know as probability theory began when a friend asked him a question:
Is it profitable to bet that one can get a double 6 within 24 rolls of a pair of dice?
To solve this problem, we have
The probability of rolling a double 6 is \(\frac{1}{36}\).
The probability of not rolling a double 6 on the first roll is \(1 - \frac{1}{36} = \frac{35}{36}\).
Therefore the probability of not rolling a double 6 in 24 consecutive times is \((\frac{35}{36})^{24} \approx 0.49\)
Also, we can write a stochastic program to simulate this game.
from scripts.testFuncs import test1
test1()
Run Simulation of Pascal's Game
Probability of winning = 0.5002
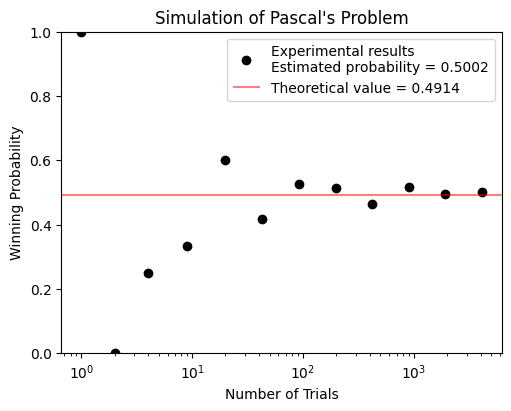
What have we learned in the Pascal’s problem?#
As the number of trials increases, the winning probability tempts to converge.
According to our derivation, the probability of not rolling a double \(6\) in \(24\) consecutive times is \((\frac{35}{36})^{24} \approx 0.4914\).
After this simulation, we can confirm that this is truth.
\(\pi\) Estimation#
One of the most historical achievement in mathematics is the estimation of the mathematical constant, \(\pi\). The approximation reached an accuracy within \(0.04%\) of the true value before the beginning of the Common Era. Nowadays, the current record of approximation error is within 100 trillion (\(10^{14}\)) digits.
Long before computers were invented, the French mathematicians Buffon (1707-1788) and Laplace (1749-1827) proposed using a stochastic simulation to estimate the value of \(\pi\).
Today, we are going to use the computer to solve this issue.
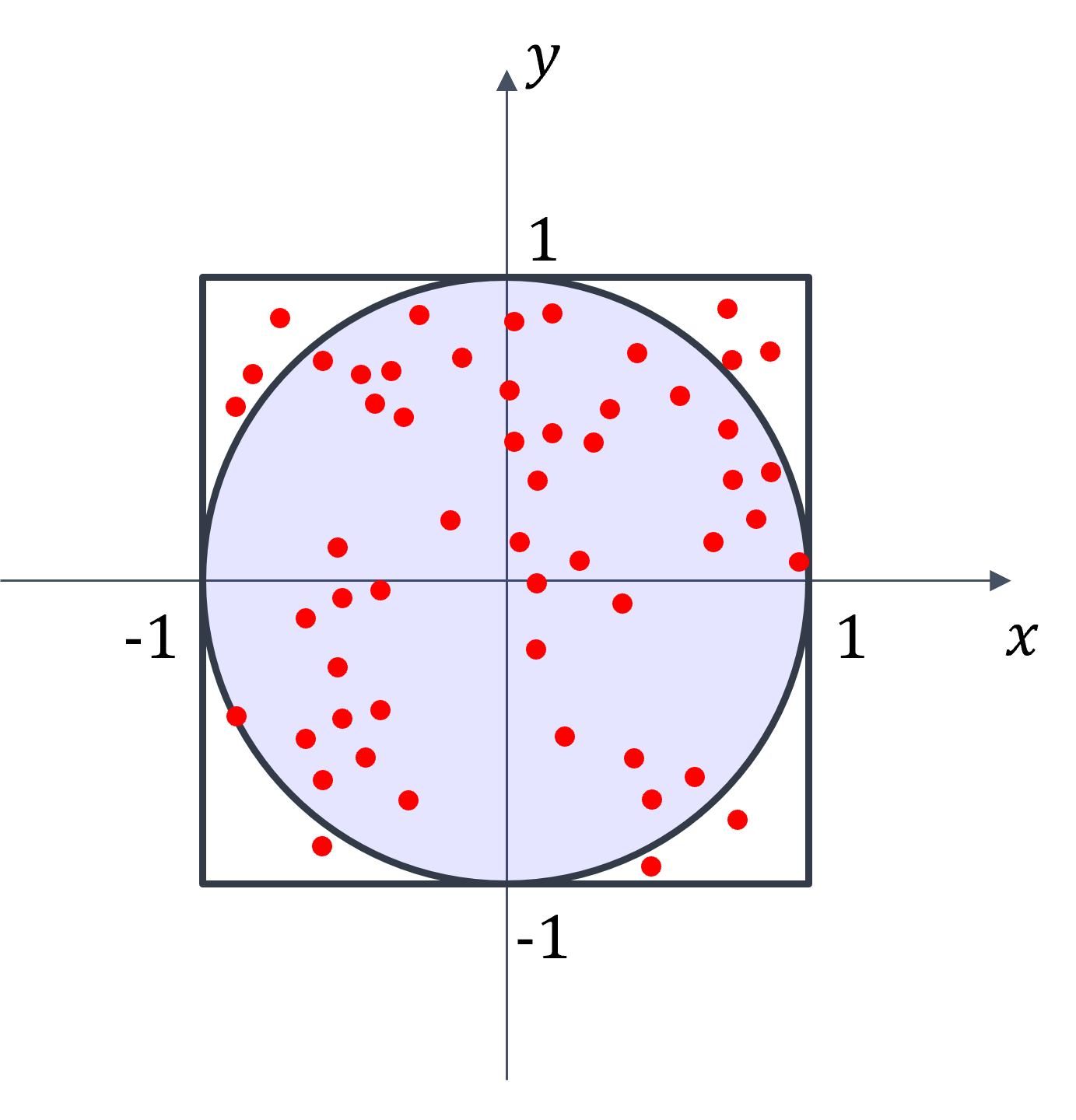
To solve this, let’s assume \(P_0 (x,y)\) is a point sampled from \(R = [-1,1] \times [-1,1]\). What we are interesting is the probability that \(P_0\) is in the circle?
The area of the square is \(A_1 = 4\).
The area of the circle is \(A_2 = \pi \cdot 1^2 = \pi\).
The probability that \(P_0\) is in the circle is \(\frac{A_2}{A_1} = \frac{\pi}{4}\).
Let’s assume we have \(N\) points which are uniformly sampled from \(R = [-1,1] \times [-1,1]\). And we found that \(m\) points are in the circle. We can estimate the value of \(\pi\) based on \(\pi \approx \frac{4m}{N}\).
Also, we can write a stochastic program to simulate this estimation.
from scripts.testFuncs import test2
test2(numTrials=100, toPrint=True)
Est. = 3.000000, STD = 1.732051, numData = 1
Est. = 3.020000, STD = 1.216388, numData = 2
Est. = 3.210000, STD = 0.765441, numData = 4
Est. = 3.051429, STD = 0.662562, numData = 7
Est. = 3.107500, STD = 0.434820, numData = 16
Est. = 3.063750, STD = 0.290202, numData = 32
Est. = 3.158730, STD = 0.212556, numData = 63
Est. = 3.158110, STD = 0.137278, numData = 127
Est. = 3.131562, STD = 0.097332, numData = 256
Est. = 3.167266, STD = 0.076953, numData = 512
Est. = 3.143047, STD = 0.052381, numData = 1024
Est. = 3.136738, STD = 0.037641, numData = 2048
Est. = 3.142408, STD = 0.027315, numData = 4095
Est. = 3.141922, STD = 0.018067, numData = 8191
Est. = 3.139659, STD = 0.012361, numData = 16383
Est. = 3.141226, STD = 0.009854, numData = 32768
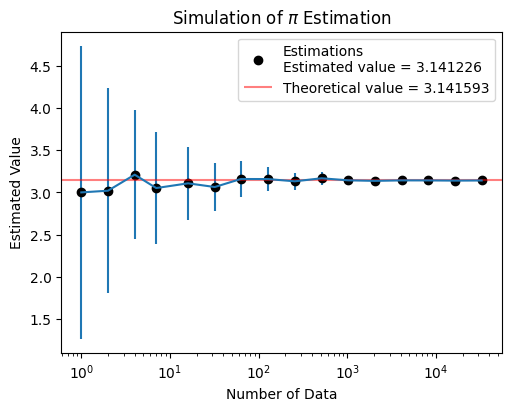
What have we learned in the \(\pi\) Estimation?#
As the number of data increases, the estimated value tempts to converge and the standard deviation of estimations is decreasing.
According to our simulation, we can only get a “close” result of \(\pi\), which means that we will never acquire an correct answer.
Limit Theorems#
Law of large numbers#
The Expectation of Sample Means (The Means of the Samples)#
Why can we acquire an estimation that is more and more accurate as the number of data increasing?
For independent and identically distributed (i. i. d.) random variables \(X_1, X_2, \dots, X_n\), the sample mean \(\bar{X}\) is defined as
Since the \(X_i\)’s are random variables, the sample mean \(\bar{X}\) is also a random variable. Thus we have
The above equation means that, as the number of sample increasing, the expectation of sample means is equal to the expectation of the population mean.
The Variance of the Sample Means#
Also, the variance of the sample mean \(\bar{X}\) is given by
This means that, as the number of sample increasing, the variance of the sample means is equal to the variance of the population divided by the sample size, n.
Therefore, we get the weak law of large numbers (WLLN). For any \(\epsilon > 0\),
The Central Limit Theorem (CLT)#
Given a set of sufficiently large samples drawn from the same population, the sample means will be approximately normally distributed, i.e., the distribution of sample means will be a normal distribution.
This normal distribution will have a mean close to the mean of the population.
The variance of the sample means will be close to the variance of the population divided by the sample size.
Monte Carlo method#
A numerical approach for acquiring an approximate solution of a problem that is difficult to solve its analytical solution.
It is an approximate solution based on the law of large numbers. This implies that it can only provide a close enough solution, not correct answer.
General flowchart:
Define a domain of possible inputs.
Generate inputs randomly from a probability distribution over the domain.
Perform a deterministic computation on the inputs.
Aggregate the results.
1. Area Estimation#
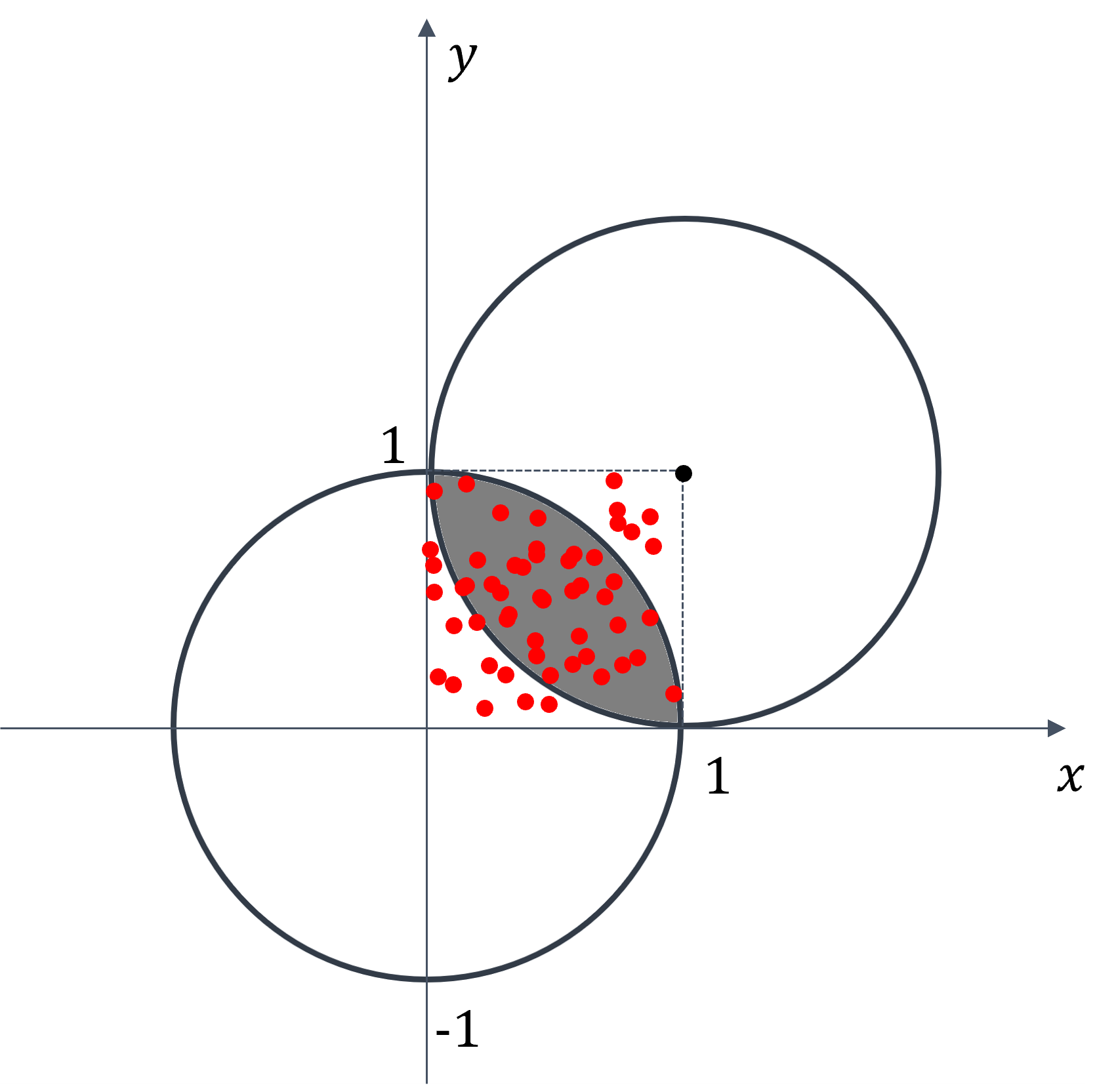
Calculate the area of gray region.
Domain of possible inputs: \( x, y \in [0, 1]\)
Randomly and uniformly generate \(N\) samples over the domain.
Count 1 if the sample satisfies the conditions (\( M = M +1 \))
\[\begin{split} x^2 + y^2 \leq 1 \\ (x-1)^2 + (y-1)^2 \leq 1 \end{split}\]Aggregate the result by
\[ \text{Estimation} = \frac{M}{N} \]
from scripts.testFuncs import test3
test3(numTrials=100, toPrint=True)
Est. = 0.62000, STD = 0.48539, numData = 1
Est. = 0.53000, STD = 0.35930, numData = 2
Est. = 0.55500, STD = 0.25880, numData = 4
Est. = 0.57857, STD = 0.18336, numData = 7
Est. = 0.58375, STD = 0.13353, numData = 16
Est. = 0.57656, STD = 0.08355, numData = 32
Est. = 0.57683, STD = 0.06370, numData = 63
Est. = 0.57157, STD = 0.04089, numData = 127
Est. = 0.57113, STD = 0.03113, numData = 256
Est. = 0.57281, STD = 0.02101, numData = 512
Est. = 0.56837, STD = 0.01514, numData = 1024
Est. = 0.57169, STD = 0.01088, numData = 2048
Est. = 0.57100, STD = 0.00743, numData = 4095
Est. = 0.57133, STD = 0.00583, numData = 8191
Est. = 0.56974, STD = 0.00384, numData = 16383
Est. = 0.57097, STD = 0.00268, numData = 32768
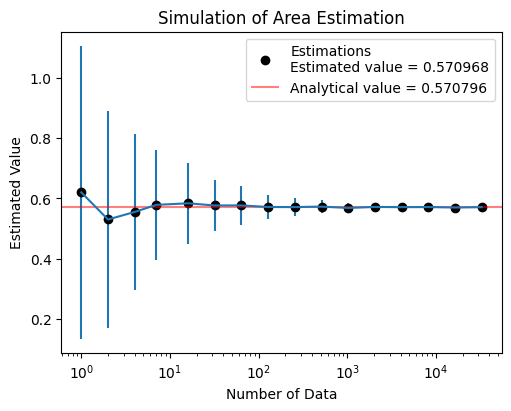
2. Univariate Integration#
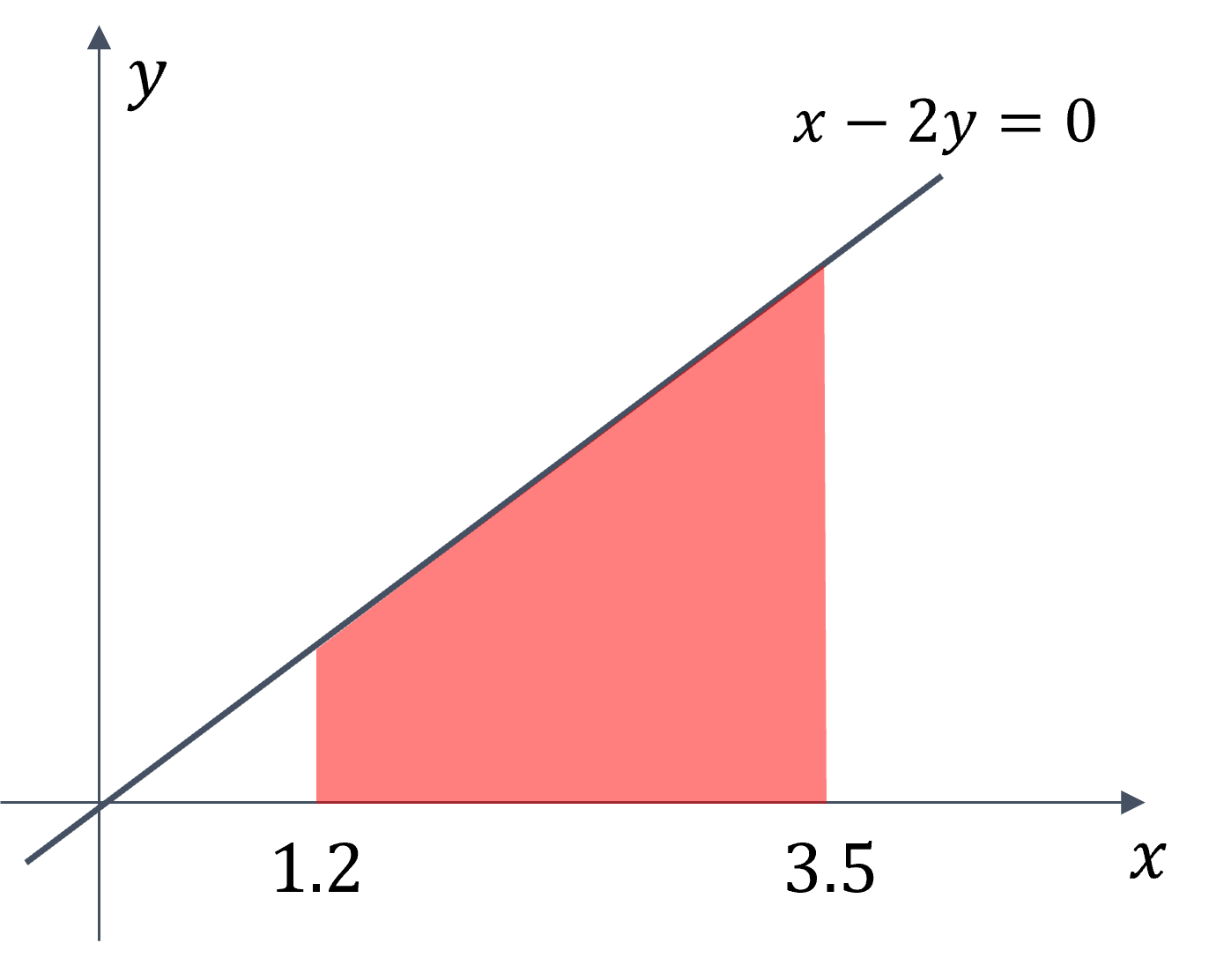
Given an univariate function \(f(x)\), calculate a definite integral \(I\) from \(a\) to \(b\).
\[\begin{split} I = \int_{a}^{b} {f(x)} \,{\rm d}x \\ f(x) = \frac{x}{2} \end{split}\]Domain of possible inputs: \( x \in [1.2, 3.5]\)
Randomly and uniformly generate \(N\) samples over the domain.
Calculate \(E_N\) as an approximation of \(I\)
\[ E_N = \frac{(b-a)}{N} \sum_{i=1}^{N} f(x_i) \]
from scripts.testFuncs import test4
test4(numTrials=100)
Est. = 2.55601, STD = 0.76504, numData = 1
Est. = 2.71303, STD = 0.53857, numData = 2
Est. = 2.72109, STD = 0.35670, numData = 4
Est. = 2.65438, STD = 0.27634, numData = 7
Est. = 2.69776, STD = 0.19578, numData = 16
Est. = 2.71971, STD = 0.14386, numData = 32
Est. = 2.70841, STD = 0.10180, numData = 63
Est. = 2.71391, STD = 0.06783, numData = 127
Est. = 2.70294, STD = 0.04930, numData = 256
Est. = 2.70789, STD = 0.03515, numData = 512
Est. = 2.70602, STD = 0.02558, numData = 1024
Est. = 2.70404, STD = 0.01617, numData = 2048
Est. = 2.70253, STD = 0.01254, numData = 4095
Est. = 2.70295, STD = 0.00935, numData = 8191
Est. = 2.70268, STD = 0.00532, numData = 16383
Est. = 2.70269, STD = 0.00423, numData = 32768
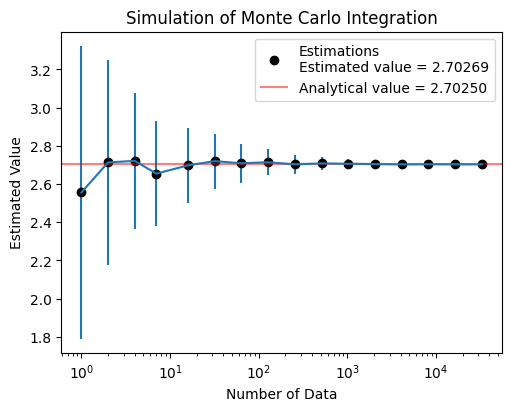
Exercise 3.1: Monte Carlo Integration#
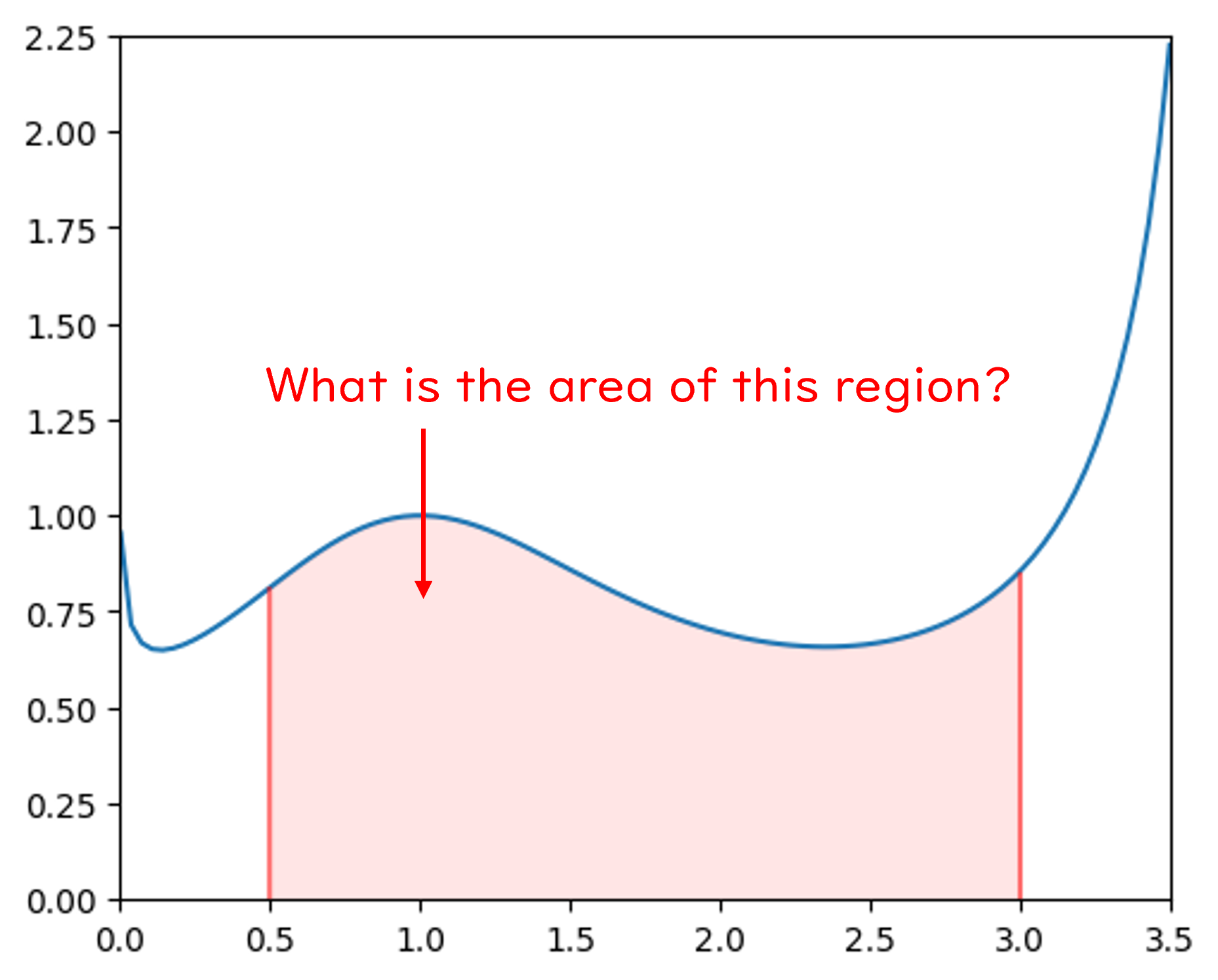
Please estimate the area of function \(f(x)\) from 0.5 to 3.0 based on Monte Carlo method.
Please repeat your estimation 100 times. The standard deviation of your estimation in these 100 trials should be less than 0.01.
3. Monte Carlo Integration (multi-variate)#
Given a multi-variate function \(f(\mathbf{x})\), calculate a definite integral \(I\) in domain \(\Omega\).
\[\begin{split} I = \iint_{\Omega}^{} {f(x, y)} \,{\rm d}x {\rm d}y \\ \end{split}\]Domain of possible inputs: \( \mathbf{x} = (x, y) \in \Omega\)
Randomly and uniformly generate \(N\) samples over the domain.
Calculate \(E_N\) as an approximation of \(I\)
\[ E_N = \frac{\text{Area}(\Omega)}{N} \sum_{i=1}^{N} f(\mathbf{x}_i) \]However, the shape of domain \(\Omega\) will affect the result of your estimation.
3.1 Multi-variate Monte Carlo Integration on Rectangular Domain#
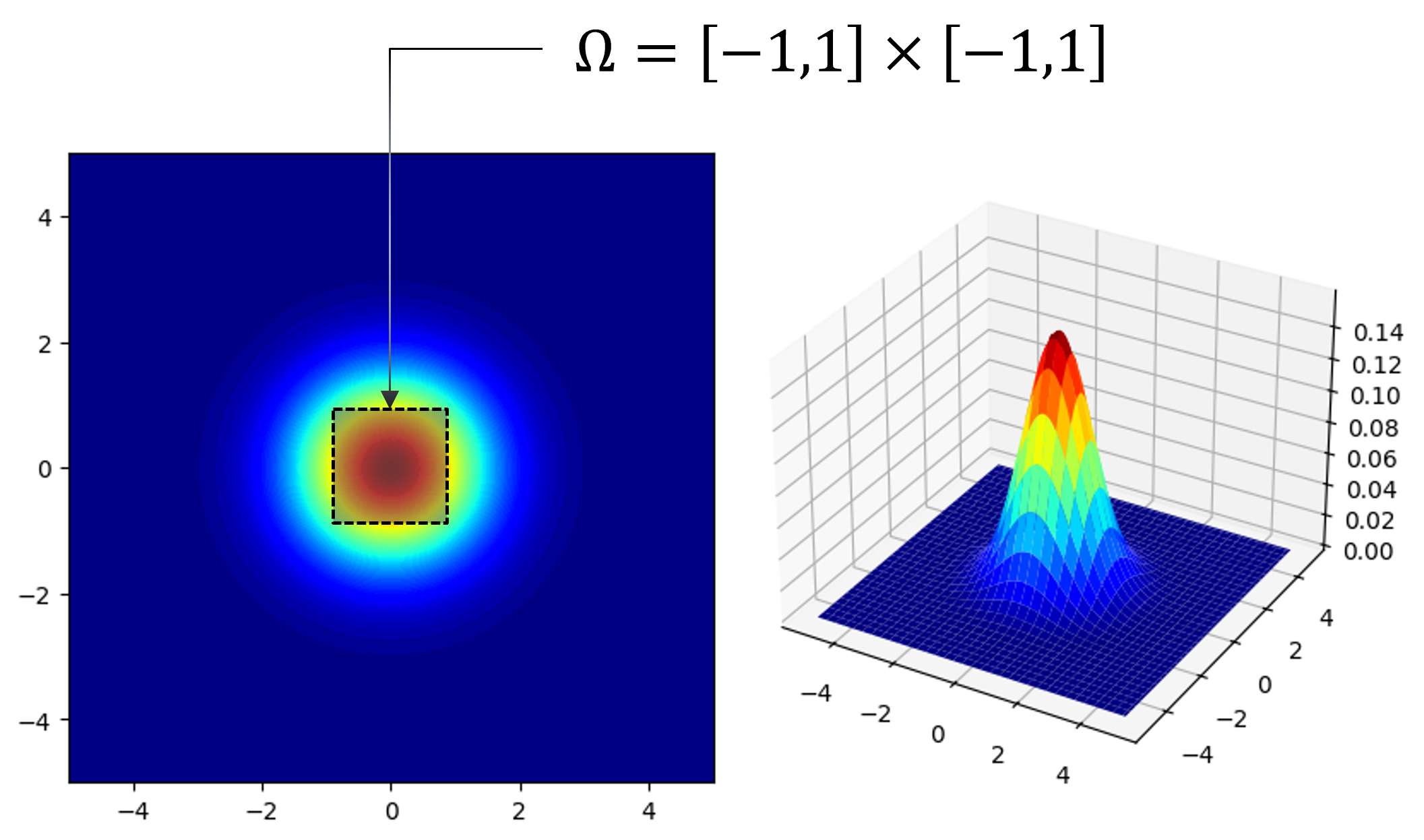
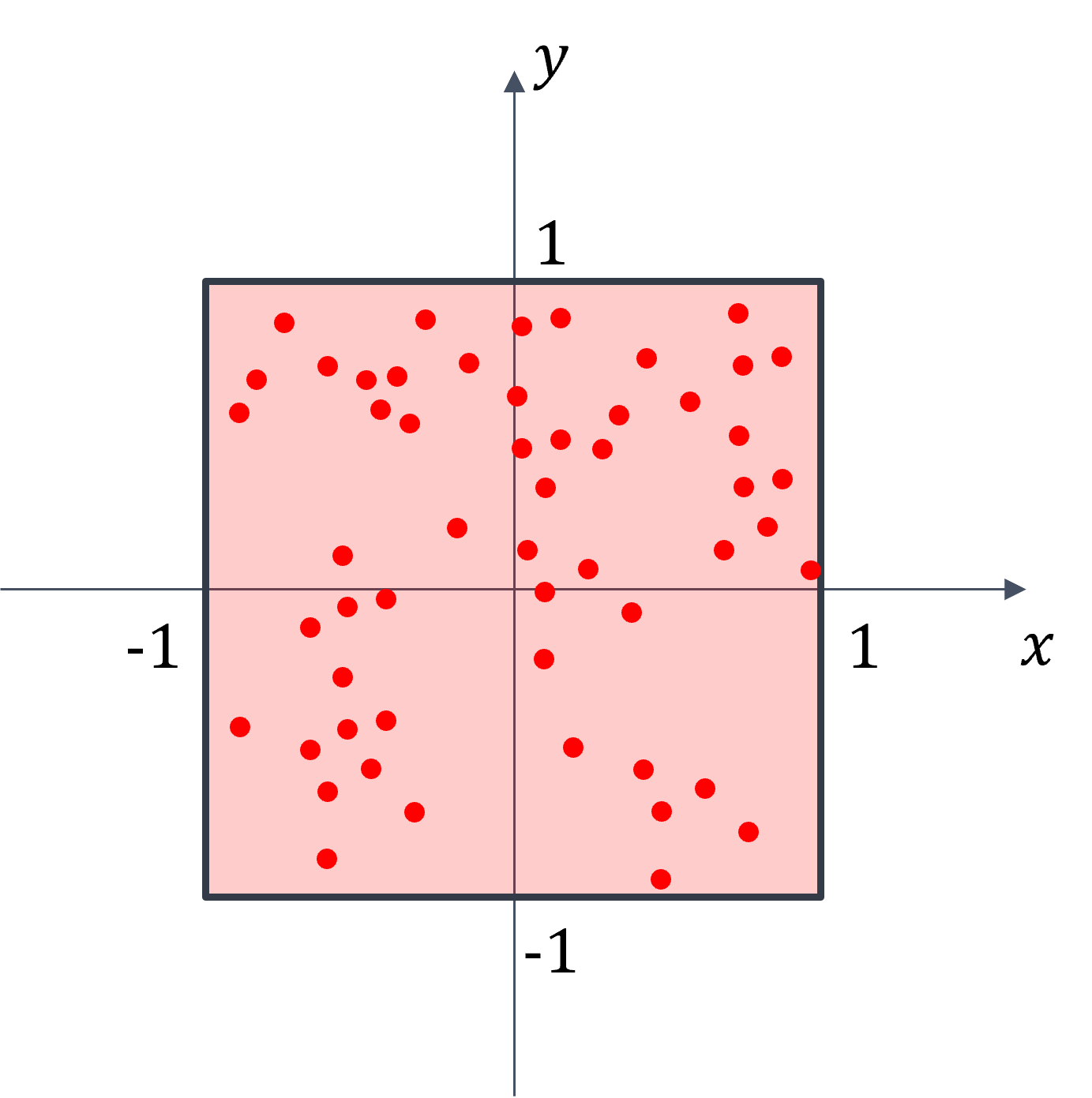
Given a multi-variate function \(f(\mathbf{x})\), calculate a definite integral \(I\) in domain \(\Omega = [-1,1] \times [-1,1]\).
\[\begin{split} I = \iint_{\Omega}^{} {f(x, y)} \,{\rm d}x {\rm d}y \\ f(x, y) = \frac{1}{2 \pi} \exp{ [- \frac{1}{2} (x^2 + y^2)] } \end{split}\]Domain of possible inputs: \( \mathbf{x} \in \Omega = [-1,1] \times [-1,1]\)
Randomly and uniformly generate \(N\) samples over the domain \(\Omega = [-1,1] \times [-1,1]\).
Calculate \(E_N\) as an approximation of \(I\)
\[ E_N = \frac{\text{Area}(\Omega)}{N_{\Omega}} \sum_{i=1}^{N_{\Omega}} f(\mathbf{x}_i) \]
3.2 Multi-variate Monte Carlo Integration on Non-rectangular Domain#
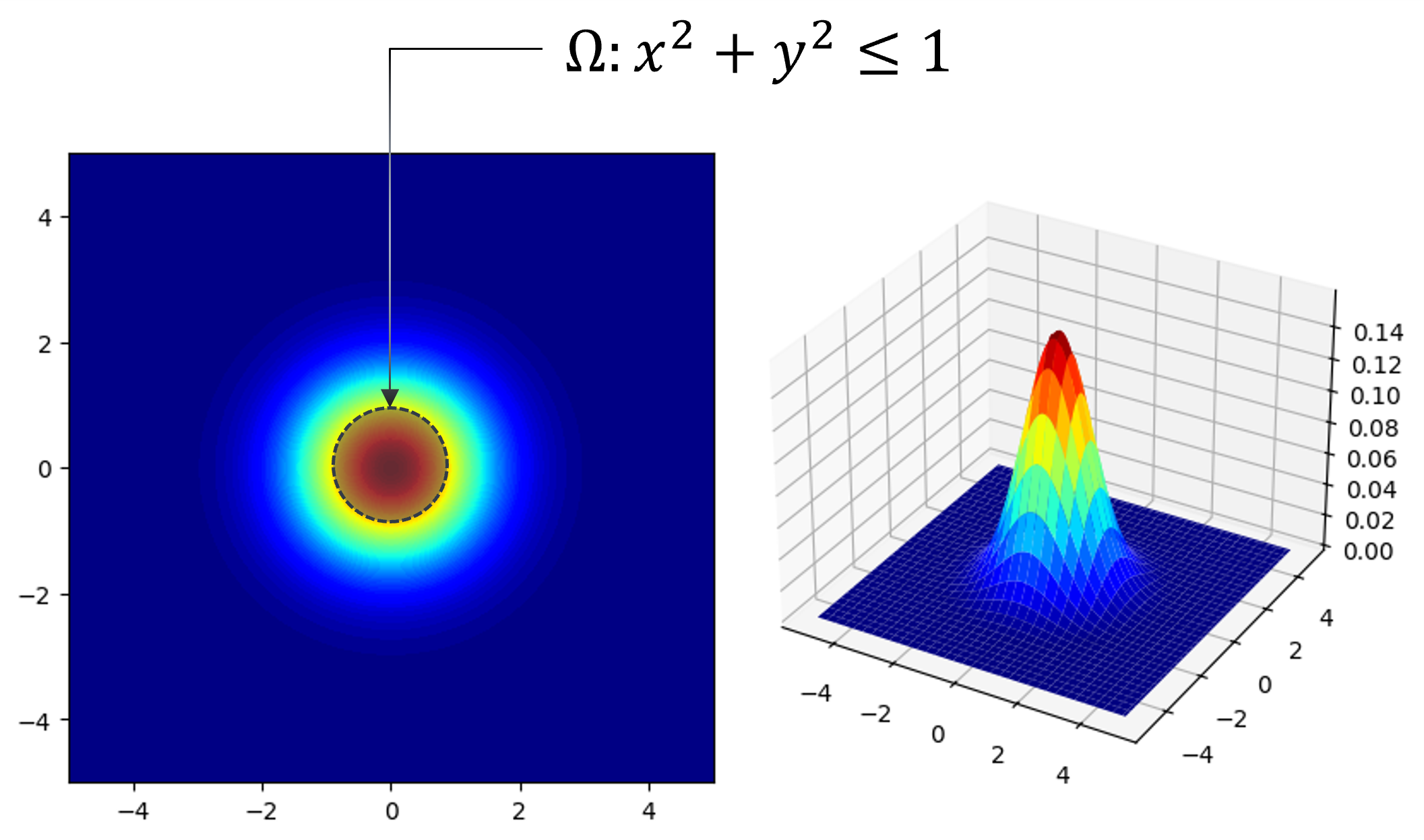
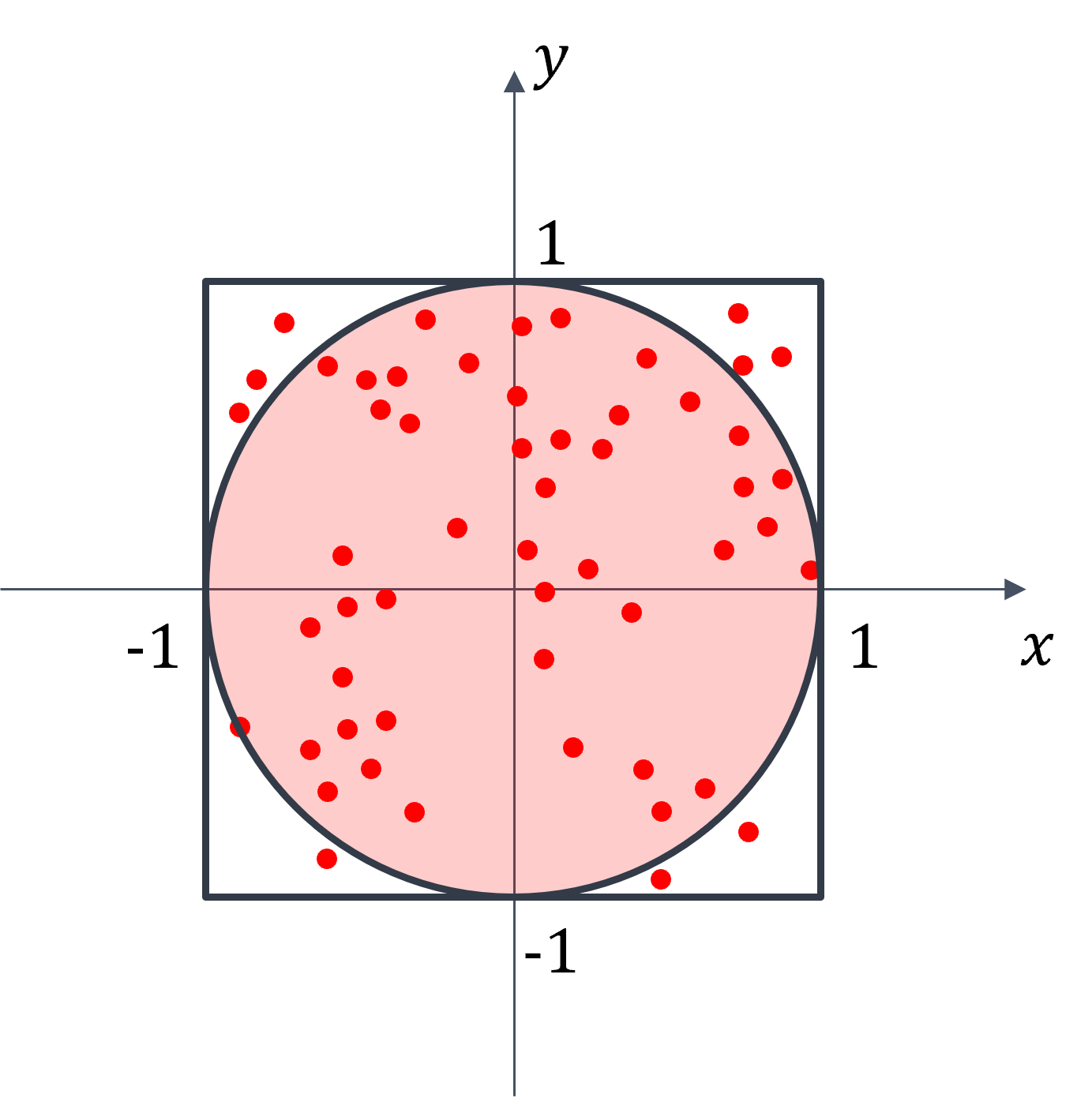
Given a multi-variate function \(f(\mathbf{x})\), calculate a definite integral \(I\) in domain \(\Omega : x^2 + y^2 \leq 1\).
\[\begin{split} I = \iint_{\Omega}^{} {f(x, y)} \,{\rm d}x {\rm d}y \\ f(x, y) = \frac{1}{2 \pi} \exp{ [- \frac{1}{2} (x^2 + y^2)] } \end{split}\]Domain of possible inputs: \( \mathbf{x} \in R = [-1,1] \times [-1,1]\)
Randomly and uniformly generate \(N_R\) samples over the domain \(R = [-1,1] \times [-1,1]\).
Keep the samples in the domain \(\Omega\). The number of samples in the domain is approximately \(N_{\Omega}\).
Calculate \(E_N\) as an approximation of \(I\)
\[\begin{split} E_N = \frac{\text{Area}(\Omega)}{N} \sum_{i=1}^{N} f(\mathbf{x}_i) = \frac{\text{Area}(R)}{N_{R}} \sum_{i=1}^{N_{\Omega}} f(\mathbf{x}_i) \\ \because \frac{N_{\Omega}}{N_R} = \frac{\text{Area}(\Omega)}{\text{Area}(R)} \end{split}\]
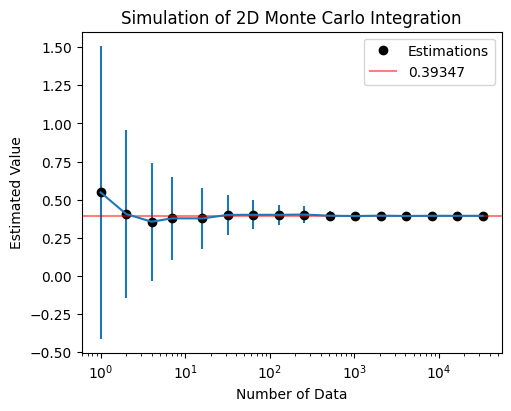
from scripts.testFuncs import test5
L = 2
test5(numTrials=64, a=(-L, -L), b=(L, L))
Est. = 0.54766, STD = 0.95771, numData = 1
Est. = 0.40631, STD = 0.54856, numData = 2
Est. = 0.35540, STD = 0.38754, numData = 4
Est. = 0.37765, STD = 0.27140, numData = 7
Est. = 0.37724, STD = 0.20225, numData = 16
Est. = 0.40019, STD = 0.13162, numData = 32
Est. = 0.40087, STD = 0.09569, numData = 63
Est. = 0.40064, STD = 0.06545, numData = 127
Est. = 0.40239, STD = 0.05498, numData = 256
Est. = 0.39493, STD = 0.03288, numData = 512
Est. = 0.39251, STD = 0.02482, numData = 1024
Est. = 0.39512, STD = 0.01771, numData = 2048
Est. = 0.39293, STD = 0.01195, numData = 4095
Est. = 0.39429, STD = 0.00956, numData = 8191
Est. = 0.39395, STD = 0.00582, numData = 16383
Est. = 0.39432, STD = 0.00404, numData = 32768
Exercise 3.2: Multi-variate Monte Carlo Integration#
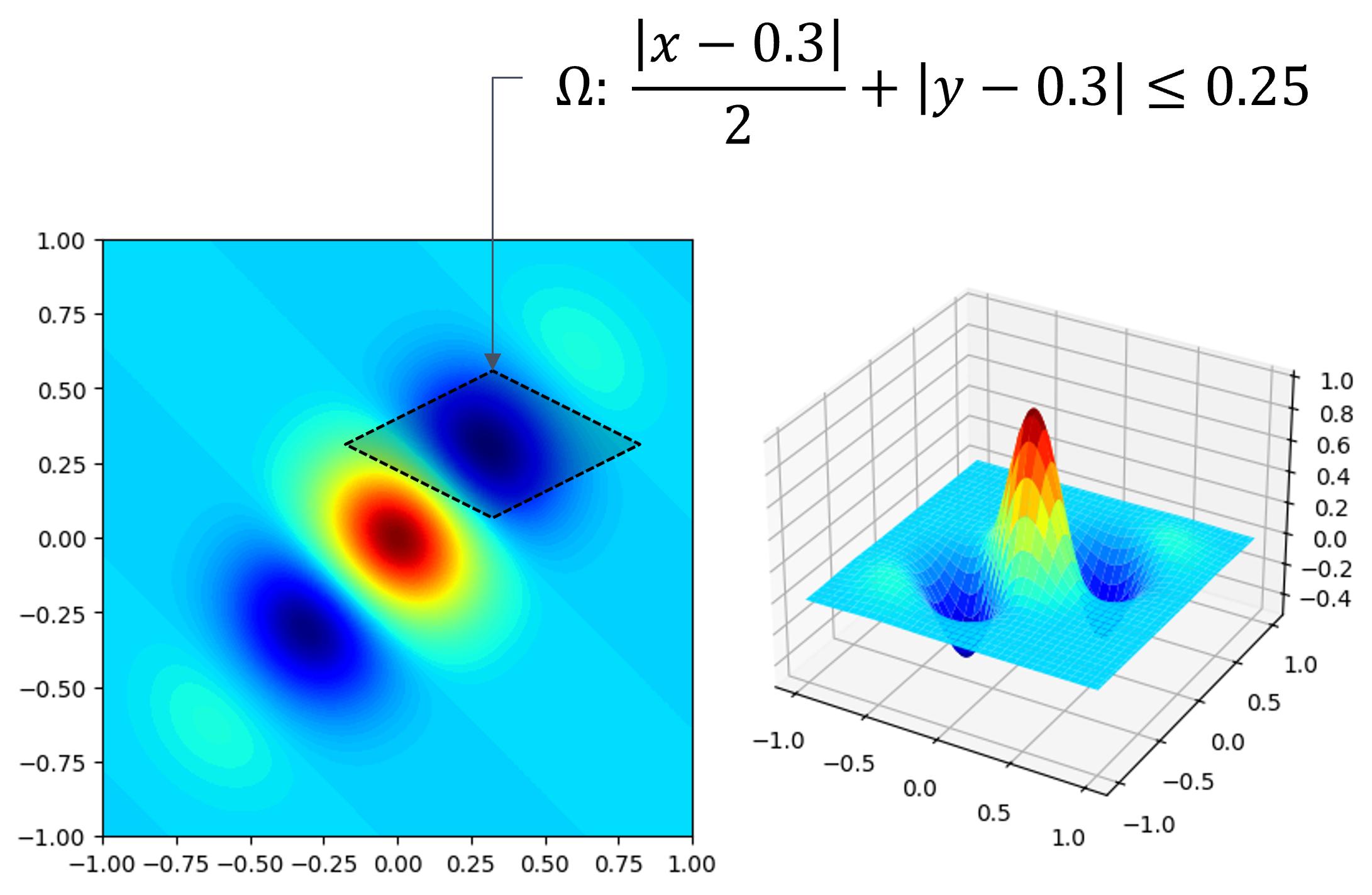
Please estimtate the definite integral of function \(f(x, y)\) over domain \(\Omega\) based on Monte Carlo method.
The condition of this exercise:
Please repeat your estimation 100 times. The standard deviation of your estimation in these 100 trials should be less than 0.01.
Summary of Monte Carlo Method#
A numerical approach for acquiring an approximate solution of a problem that is difficult to solve its analytical solution.
It is an approximate solution based on the law of large numbers. This implies that it can only provide a close enough solution, not correct answer.
General flowchart:
Define a domain \(\Omega\) of possible inputs, \(\mathbf{x} \in \Omega\).
Randomly generate \(N_R\) samples from a probability distribution (usually use uniform distribution) over the domain \(R\). The target domain \(\Omega\) should be in the domain \(R ( \Omega \in R )\).
Keep the samples in the domain \(\Omega\). The number of samples in the domain is approximately \(N_{\Omega}\).
Perform a deterministic computation on the inputs.
Aggregate the results.
Don't click this
-
Exercise 3.1
import matplotlib.pyplot as plt import numpy as np import random from scipy.integrate import quad from .utils import getIntegralEst def exercise1(numTrials=100, numData=2**15, **kwargs): a = kwargs.get("a", 0.5) b = kwargs.get("b", 3.) func = kwargs.get("func", lambda x: (1 + np.sin(x) * (np.log(x))**2)**(-1)) toPrint = kwargs.get("toPrint", True) xVals, yEsts, yStds= [], [], [] xAxis = np.geomspace(1, numData, 16, dtype=np.int64) for val in xAxis: curEst, std = getIntegralEst( numData=val, numTrials=numTrials, a=a, b=b, func=func ) xVals.append(val) yStds.append(std) yEsts.append(curEst) if toPrint: print("Est. = {:.05f}, STD = {:.05f}, numData = {}".format(curEst, std, val)) fig = plt.figure(figsize=(5,4), dpi=100, layout="constrained", facecolor="w") ax1 = fig.add_subplot(111) ax1.errorbar( x=xVals, y=yEsts, yerr=yStds, ) ax1.plot(xAxis, yEsts, 'ko', label="Estimations") ax1.set_title("Exercise 1") ax1.set_xlabel("Number of Data") ax1.set_ylabel("Estimated Value") ax1.set_xscale("log") xMin, xMax = ax1.get_xlim() scipyResult = quad(func=func, a=a, b=b) ax1.hlines( scipyResult[0], xmin = xMin, xmax = xMax, colors = 'r', alpha = 0.5, label = "{:.05f}".format(scipyResult[0]) ) ax1.legend(loc="best") plt.show()
-
Exercise 3.2
import matplotlib.pyplot as plt import numpy as np import random from scipy.integrate import quad def exercise2(numTrials=100, numData=2**15, **kwargs): def est4exercise2(numData, numTrials, a, b, func): estimates = [] for t in range(numTrials): integralGuess = mcFunc4exercise2(numData, a=a, b=b, func=func) estimates.append(integralGuess) std = np.std(estimates) curEst = sum(estimates)/len(estimates) return (curEst, std) def mcFunc4exercise2(numData, a, b, func): I = 0. a1, a2, b1, b2 = a[0], a[1], b[0], b[1] for data in range(numData): x = (b1-a1)*random.random() + a1 y = (b2-a2)*random.random() + a2 if abs(x-0.3)/2 + abs(y-0.3) <= 0.25: I += func(x, y) return 1*0.5*0.5*I/numData def gabor(x, y): """Simple version Gabor function for Monte Carlo""" sigma, theta, gamma = 0.4, np.pi/4, 2 sigma_x = sigma sigma_y = sigma / gamma # Rotation x_theta = x * np.cos(theta) + y * np.sin(theta) y_theta = -x * np.sin(theta) + y * np.cos(theta) gb = np.exp( -0.5 * (x_theta**2 / sigma_x**2 + y_theta**2 / sigma_y**2) ) * np.cos(2 * np.pi * x_theta) return gb a = kwargs.get("a", (-0.2, 0.05)) b = kwargs.get("b", (0.8, 0.55)) func = kwargs.get("func", gabor) toPrint = kwargs.get("toPrint", True) xVals, yEsts, yStds= [], [], [] xAxis = np.geomspace(1, numData, 16, dtype=np.int64) for val in xAxis: curEst, std = est4exercise2( numData=val, numTrials=numTrials, a=a, b=b, func=func, ) xVals.append(val) yStds.append(std) yEsts.append(curEst) if toPrint: print("Est. = {:.05f}, STD = {:.05f}, numData = {}".format(curEst, std, val)) fig = plt.figure(figsize=(5,4), dpi=100, layout="constrained", facecolor="w") ax1 = fig.add_subplot(111) ax1.errorbar( x=xVals, y=yEsts, yerr=yStds, ) ax1.plot(xAxis, yEsts, 'ko', label="Estimations") ax1.set_title("Simulation of 2D Monte Carlo Integration") ax1.set_xlabel("Number of Data") ax1.set_ylabel("Estimated Value") ax1.set_xscale("log") ax1.legend(loc="best") plt.show()