17. Random Walks and Stochastic Programs#
Last Time#
Knapsack problems
The 0/1 knapsack problems
Dynamic programming
Graph theory
Graph optimization problems
Breadth-first search
Depth-first search
Dijkstra algorithm
Today#
- Part I: Random Walk
-
Part II: Stochastic Programs
- The concept of random variables
- Distributions For discrete random variables For continuous random variables
Random Walks#
In 1827, the Scottish botanist Robert Brown observed that pollen particles suspended in water seemed to float around at random.
Random walks are widely used to model many different processes:
Physical processes (e.g., diffusion)
Biological processes (e.g., the kinetics of displacement of RNA from heteroduplexes by DNA)
Social processess (e.g., movements of the stock market)
It provides us with a good example of how to use abstract data types and inheritance to structure programs in general and simulation models in particular.
The Drunkard’s Walk#
A drunkard is standing in the middle of a field.
Every second the drunkard takes one step in a random direction.
What is his/her expected distance from the origin in 1000 seconds?
If he/she takes many steps, is he/she likely to move ever farther from the origin or not?
import scripts.part1 as p1
p1.test1()
Run Test #1: Random Walk of Drunkard HoHoChen
UsualDrunk random walk of 10 steps
Mean = 2.810, Max = 7.1, Min = 0.0
UsualDrunk random walk of 100 steps
Mean = 8.749, Max = 18.6, Min = 0.0
UsualDrunk random walk of 1000 steps
Mean = 31.840, Max = 69.6, Min = 0.0
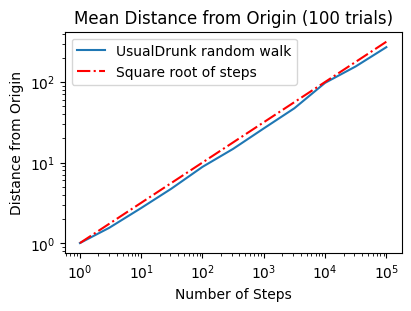
UsualDrunk random walk of 10000 steps
Mean = 87.033, Max = 224.2, Min = 4.2
==================== End of Test 1 ====================
p1.test2()
Run Test #2: Random Walk of Drunkard YenYenChen
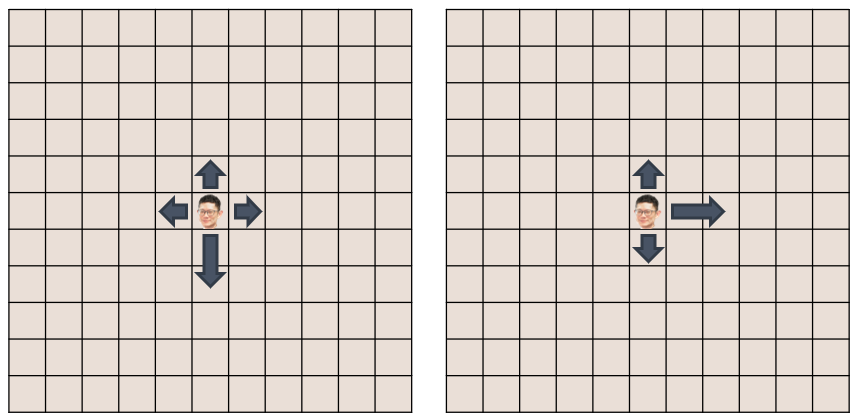
Biased Random Walks#
A drunkard with special behavior
For example:
A drunkard in the southern hemisphere who hates the heat is able to move twice as fast when his random movements take him in a southward direction, even in his drunken stupor.
A TSMC employee who lives in the western coast of Taiwan wants to run away from his company. After drinking heavily, he is able to move twice as fast when his random movements take him in a eastward direction.
…
p1.test3()
Run Test #3: Random Walk of Drunkard YingYingChen
UsualDrunk random walk of 100 steps
Mean = 9.835, Max = 24.4, Min = 0.0
UsualDrunk random walk of 1000 steps
Mean = 29.005, Max = 65.4, Min = 6.3
HeatAvoidDrunk random walk of 100 steps
Mean = 25.839, Max = 57.3, Min = 7.6
HeatAvoidDrunk random walk of 1000 steps
Mean = 248.676, Max = 330.1, Min = 175.5
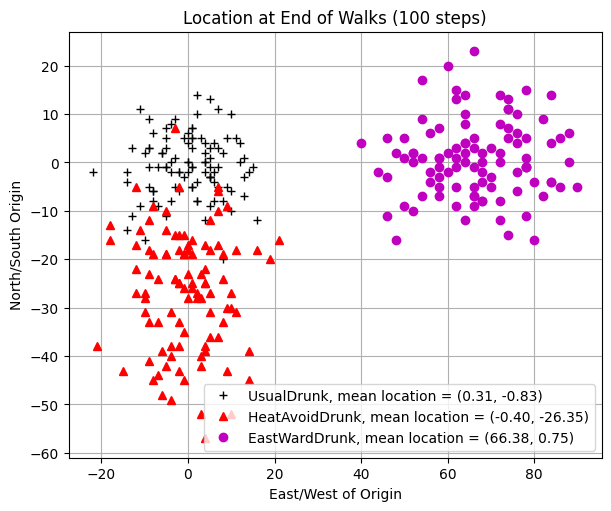
EastWardDrunk random walk of 100 steps
Mean = 66.386, Max = 94.1, Min = 46.0
EastWardDrunk random walk of 1000 steps
Mean = 662.854, Max = 726.5, Min = 594.1
==================== End of Test 3 ====================
p1.test4()
Run Test #4: Random Walk of Drunkard ChihChihChen
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[4], line 1
----> 1 p1.test4()
File O:\Personal_GitHub\nycudopcs_jb\chapters\17\scripts\part1\testFuncs.py:105, in test4(numTrials, name)
103 for k in range(len(drunkKinds)):
104 for i in range(len(steps)):
--> 105 distances = simWalks(steps[i], numTrials, drunkKinds[k], name)
106 result[i,k] = np.mean(distances)
108 fig = plt.figure(1, figsize=(4,3), dpi=100, layout="constrained")
File O:\Personal_GitHub\nycudopcs_jb\chapters\17\scripts\part1\utils.py:26, in simWalks(numSteps, numTrials, dClass, name)
24 f = Field()
25 f.addDrunk(drunkard, origin)
---> 26 distances.append(round(walk(f, drunkard, numSteps), 1))
27 return distances
File O:\Personal_GitHub\nycudopcs_jb\chapters\17\scripts\part1\utils.py:14, in walk(field, target, numSteps)
12 start = field.getLoc(target)
13 for s in range(numSteps):
---> 14 field.moveDrunk(target)
15 return start.distFrom(field.getLoc(target))
File O:\Personal_GitHub\nycudopcs_jb\chapters\17\scripts\part1\objs.py:48, in Field.moveDrunk(self, drunk)
46 xDist, yDist = drunk.takeStep()
47 currentLocation = self.drunks[drunk]
---> 48 self.drunks[drunk] = currentLocation.move(xDist, yDist)
File O:\Personal_GitHub\nycudopcs_jb\chapters\17\scripts\part1\objs.py:15, in Location.move(self, deltaX, deltaY)
12 def __init__(self, x, y):
13 self.x, self.y = x, y
---> 15 def move(self, deltaX, deltaY):
16 return Location(self.x+deltaX, self.y+deltaY)
18 def getX(self):
KeyboardInterrupt:
# Get the Final Location
p1.test5()
Run Test #5: Where is the Drunkard Peter?
Iterator#
If you are not familiar with this, please refer here.
Sample code:
class styleIterator: def __init__(self, styles): self.index = 0 self.styles = styles def nextStyle(self): result = self.styles[self.index] if self.index == len(self.styles)-1: self.index = 0 else: self.index += 1 return result
# The Trajectory of Walks
p1.test6()
Run Test #6: Trajectory of the Drunkard Peter
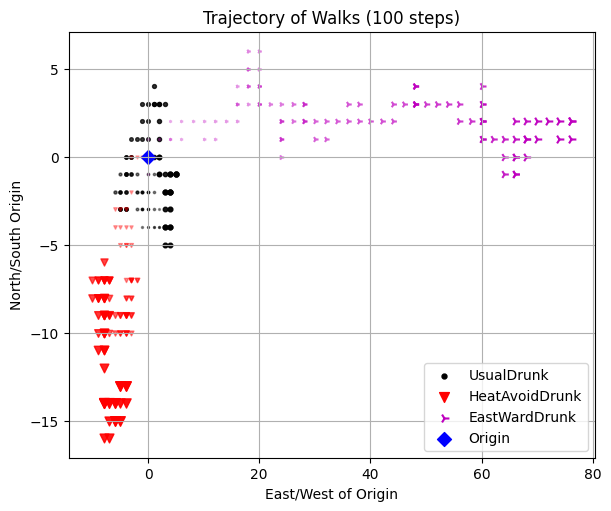
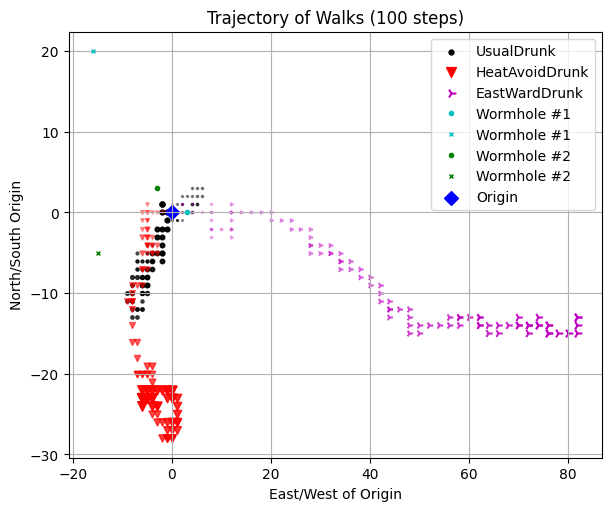
Treacherous fields#
A field with wormholes
For example:

p1.test7()
Run Test #7: Trajectory of Peter in a Mysterious Field
Stochastic Programs#
A program is deterministic if whenever it is run on the same input, it produces the same output.
If there is a program that is designed to simulate a dice game somewhere, it requires a stochastic implementation, otherwise it is a boring game.
Most programming languages, including Python, include simple ways to write stochastic programs, i.e., programs that exploit randomness.
Typically, a random number or a series of random bits is created via pseudo random number generator (PRNG), which generates random number (or bit) based on an initial value called seed.

Rolling a dice#
from scripts.part2 import test1
# Random seed
test1()
# Fixed random see
test1(seed=True)
Rolling a fair dice 5 times
1 trials: 11132
2 trials: 32356
3 trials: 15445
4 trials: 61132
5 trials: 55465
Rolling a fair dice 5 times
1 trials: 44135
2 trials: 44135
3 trials: 44135
4 trials: 44135
5 trials: 44135
Flip Coins#
Suppose you are playing a coin flip game with Harvey Dent, and if heads comes up, Harvey wins. What is the probability that Harvey wins?
from scripts.part2.utils import flipCoin
result = ""
for i in range(5):
currentResult = flipCoin()
print("{}: {}".format(i+1, currentResult))
result += currentResult
print(result)
1: T
2: T
3: T
4: T
5: T
TTTTT
We can use a systematic process to derive the precise probability of some complex event based on knowing the probability of one or more simpler events.
However, we don’t actually know the exact probability of a event (we don’t know whether the dice is fair, for example).
Fortunately, if we have some data about the behavior of the dice, we can combine that data with our knowledge of probability to derive an estimate of the true probability. This concept is called inferential statistics.
Before we start to introduce the concept of inferential statistics, let’s start with some fundamental mathematics.
The Concept of Random Variables#
When analyzing a random experiment, we usually focus on certain numerical characteristics of the experiment. For example, in a baseball game, we might be interested in the number of runs, hits, home runs, strikeouts, and walks. If we consider the entire baseball game as a random experiment, then these numerical results provide information about the outcome of the experiment, and they are examples of random variables. In short, a random variable is a real-valued variable whose value is determined by an underlying random experiment.
In essence, a random variable is a real-valued function that assigns a numerical value to each possible outcome of the random experiment. Taking the coin tossing example above, we can define the value of a random variable \(X\) to be \(0\) if the outcome is
"T"and \(1\) otherwise. Hence, the random variable \(X\) is a function from the sample space \(S = \{H, T\}\) to the real numbers \(0\) and \(1\).
Since a random variable is a function that returns you a real value represented an event in the sample space, it means we will get different results if we measure it (different experiments). Therefore, we define \(X_i\) as the \(i^{th}\) measurement of the random variable \(X\).
This means that we can also define another random variable \(Y\) to represent the summation of measurements \(X_1 + X_2 + \cdots + X_i\). Taking an example of flipping a coin 5 times, we might be interested in how many heads we will have. In this case, the sample space \(S\) becomes \(\{ TTTTT, TTTTH, \cdots, HHHHH \}\). And the range of random variable \(Y\), shown by \(R_Y\), is the set of possible values for \(Y = X_1 + X_2 + \cdots + X_5 = \{0, 1, 2, 3, 4, 5 \}\).
from scripts.part2.utils import flip
for i in range(5):
numH, _ = flip(numFlips=5)
print("Exp. {}: {}".format(i+1, numH))
Exp. 1: 4
Exp. 2: 3
Exp. 3: 1
Exp. 4: 1
Exp. 5: 4
Probability Mass Function (PMF) & Probability Density Function (PDF)#
If \(X\) is a discrete random variable, its range \(R_X\) is a countable set, meaning we can enumerate its elements. In other words, we can express \(R_X\) as \(\{ x_1, x_2, x_3, ... \}\), where \(x_1, x_2, x_3, ...\) represent possible values of \(X\).
For a discrete random variable \(X\), we are particularly interested in the probabilities of \(X = x_k\). Here, the event \(A = \{ X = x_k \}\) consists of all outcomes \(s\) in the sample space \(S\) for which the corresponding value of \(X = x_k\). More formally, this can be expressed as:
The probabilities of these events \(P_X (x_k)\) are described by the probability mass function (PMF) of \(X\).
If \(X\) is a continuous random variable, then the probabilities of these events \(f_X (x)\) are described by the probability density function (PDF) of \(X\).
from scripts.part2.utils import flip
import matplotlib.pyplot as plt
import numpy as np
x = np.logspace(start=1, stop=4, num=4, dtype=int)
fig = plt.figure(figsize=(14,5), dpi=100)
for idx, numFlips in enumerate(x):
numH, numT = flip(numFlips=numFlips)
ax = fig.add_subplot(1, 4, idx+1)
ax.bar(
x=[0, 1],
height=[numH, numT],
)
ax.set(
title="# of Flips = {:d}".format(numFlips),
xticks=[0, 1],
xticklabels=["H", "T"],
)
plt.show()
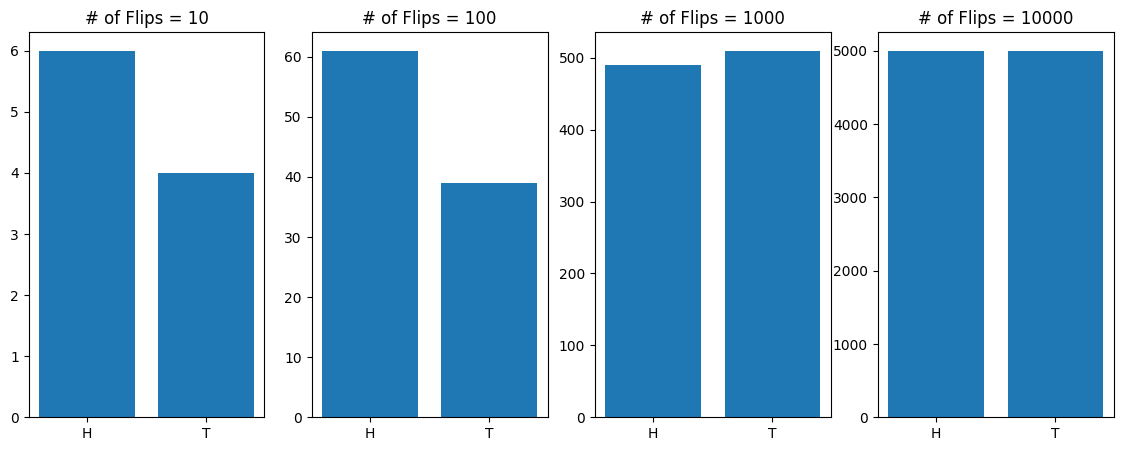
Expectation and Variance#
Consider a random variable \(X\). We would like to define its average, e.g., its expected value or mean. The expected value is defined as the weighted average of the values in the range.
Let \(X\) be a discrete random variable with range \(R_X = \{ x_1, x_2, x_3, ...\}\). The expected value of \(X\), denoted by \(\mathbb{E}[X]\), is defined as
The variance of \(X\), denoted by \(\text{Var}(X)\), is defined as
For a continuous random variable \(X\),
Properties of expectation and variance#
Expectation is linear:
Variance is not linear:
If \(X_1 + X_2 + \cdots + X_n\) are independent random variables and \(X = X_1 + X_2 + \cdots + X_n\), then
Distributions#
Certain probability distributions appear so frequently in practice that they have been given special names. Each of these distributions is associated with a specific random experiment. Because these experiments effectively model many real-world phenomena, these distributions are widely used across various applications. For this reason, they are named and studied in detail.
In this section, we will present the probability mass functions (PMFs) for these special random variables. However, instead of simply memorizing the PMFs, it is more important to understand the underlying random experiments that give rise to them.
Bernoulli Distribution#
A Bernoulli random variable is a random variable that can only take two possible values, usually \(0\) and \(1\). This random variable models random experiments that have two possible outcomes, sometimes referred to as “success” and “failure.”
For example:
You bought a lottery ticket. You either win the prize (reuslting in \(X = 1\)) or fail (\(X = 0\)).
You met a lovely girl and you invited her for a dinner. She accepted your invitation (\(X = 1\)) or rejected (\(X = 0\)).
Series tied and today is the game 7. Your team wins (\(X = 1\)) the series or loses (\(X = 0\)).
Formally, the Bernoulli distribution is defined as follows: A random variable \(X\) is said to be a Bernoulli random variable with parameter \(p\), shown as \(X \sim Bernoulli (p)\), if its PMF is given by (\(0 < p < 1\))
Expectation and variance of \(X \sim Bernoulli (p)\):
import matplotlib.pyplot as plt
import numpy as np
p = 0.4
fig = plt.figure(figsize=(4, 3), dpi=100)
ax = fig.add_subplot(111)
ax.plot([0, 1], [1-p, p], 'k.')
ax.vlines(
x=[0,1],
ymin=[0,0],
ymax=[1-p,p],
colors='k',
)
ax.set(
title=r"$X \sim Bernoulli(0.4)$",
xlim=[-1,2],
xticks=np.linspace(-1,2,4),
ylim=[0,1],
)
plt.show()
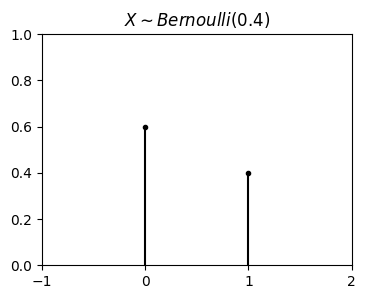
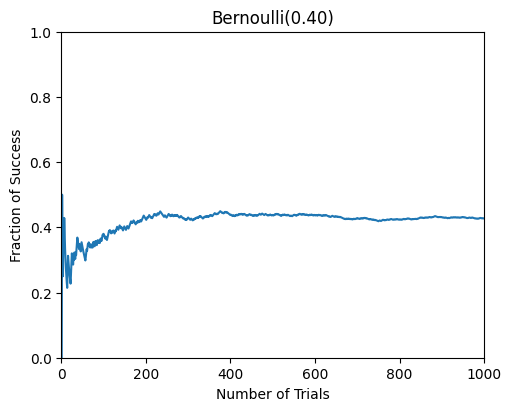
from scripts.part2.testFuncs import test2
test2(p=0.4)
Geometric Distribution#
The random experiment behind the geometric distribution is as follows. Suppose that we have a coin with \(P(Head) = p\). I toss the coin until we observe the first heads. We define \(X\) as the total number of trials in this experiment. Then \(X\) is said to have geometric distribution with parameter \(p\). In other words, it is usually thought of as describing the number of independent Bernoulli attempts required to achieve a first success (or a first failure). In this case, the range of \(X\) here is \(R_X = \{1, 2, 3, ... \}\).
For example: Looking at your past history, your chance of successfully getting a girl’s contact information on the street is \(20\%\). Then the distribution of getting the first girl’s contact information after \(k\) attempts will be geometric distribution. The mathematicall description for this case is:
A random variable \(X\) is said to be a geometric random variable with parameter \(p\), shown as \(X \sim Geometric (p)\), if its PMF is given by (\(0 < p < 1\))
Expectation and variance of \(X \sim Geometric (p)\):
import matplotlib.pyplot as plt
import numpy as np
p = 0.2
k = np.arange(1, 25)
P_k = [p * (1-p)**(i) for i in k]
fig = plt.figure(figsize=(4, 3), dpi=100)
ax = fig.add_subplot(111)
ax.plot(k, P_k, 'b.')
ax.vlines(
x=k,
ymin=np.zeros_like(k),
ymax=P_k,
colors='b',
)
ax.set(
title=r"$X \sim$" + " Geometric({:.2f})".format(p),
xlim=[0, max(k)],
ylim=[0, 0.25],
)
plt.show()
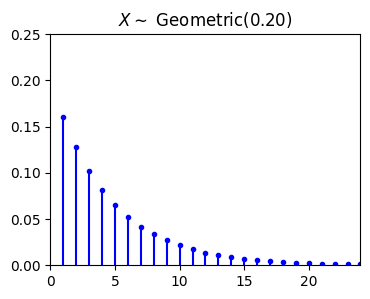
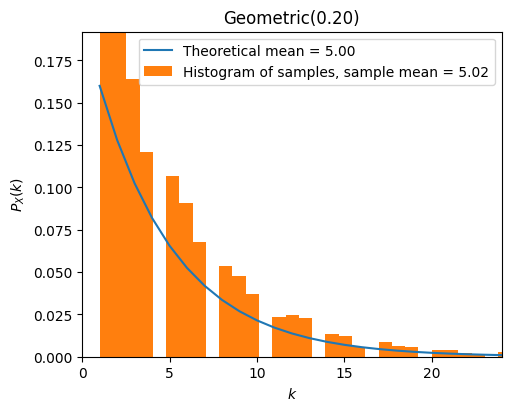
from scripts.part2.testFuncs import test3
test3(numTrials=5000, p=0.2)
Exercise XXXX#
假設成功要到聯絡資訊的機率是 \(5 \%\),請問 OOO 平均要嘗試多少次才能拿到聯絡資訊?請寫一個程式來模擬這個事件
Binomial Distribution#
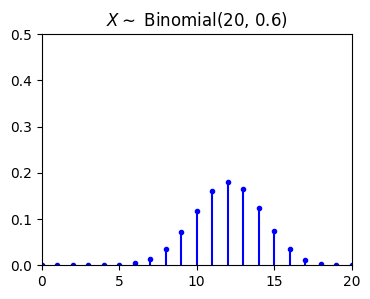
The random experiment behind the binomial distribution is as follows. Suppose that we have a coin with \(P(Head) = p\). I toss the coin \(n\) times and define \(X\) to be the total number of heads that we observe. Then \(X\) is binomial with parameter \(n\) and \(p\), \(X \sim Binomial(n,p)\). In this case, the range of \(X\) here is \(R_X = \{0, 1, 2, 3, ..., n\}\).
A random variable \(X\) is said to be a binomial random variable with parameter \(n\) and \(p\), shown as \(X \sim Binomial(n,p)\), if its PMF is given by (\(0 < p < 1\))
Expectation and variance of \(X \sim Binomial (n,p)\):
import matplotlib.pyplot as plt
import numpy as np
from scripts.part2.basicFuncs import binCoeff
p = 0.6
n = 20
k = np.arange(n+1)
P_k = [binCoeff(n=n, k=i) * p**i * (1-p)**(n-i) for i in k]
fig = plt.figure(figsize=(4, 3), dpi=100)
ax = fig.add_subplot(111)
ax.plot(k, P_k, 'b.')
ax.vlines(
x=k,
ymin=np.zeros_like(k),
ymax=P_k,
colors='b',
)
ax.set(
title=r"$X \sim$" + " Binomial({:d}, {:.1f})".format(n, p),
xlim=[0, max(k)],
ylim=[0, 0.5],
)
plt.show()
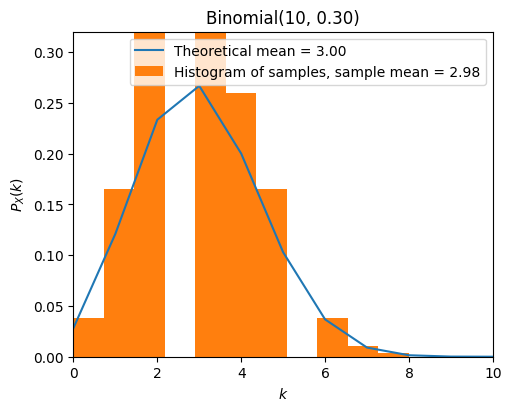
from scripts.part2.testFuncs import test4
test4(numTrials=1000, n=10, p=0.3)
Exercise XXXX#
請寫一個程式來模擬投擲一顆骰子10次出現4次6的機率分布狀況
Pascal Distribution#
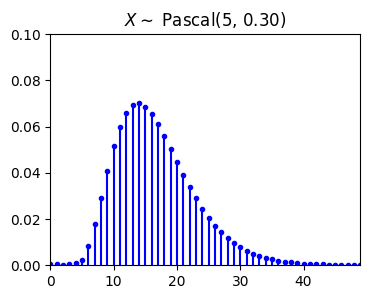
The Pascal distribution is a generalization of the geometric distribution. It relates to the random experiment of repeated independent trials until observing \(m\) successes. Suppose that we have a coin with \(P(Head) = p\). I toss the coin until we observe \(m\) heads, where \(m \in \mathbb{N}\). We define \(X\) as the total number of trials in this experiment. Then \(X\) is said to have Pascal distribution with parameter \(m\) and \(p\), \(X \sim Pascal(m,p)\). In this case, the range of \(X\) here is \(R_X = \{m, m+1, m+2, m+3, ...\}\) and \(Pascal(1, p) = Geometric(p)\).
To derive the PMF of a \(Pascal(m, p)\) random variable \(X\). We can use this fact:
We observe \(m-1\) heads in the first \(k-1\) trials. We define the probability of this event is \(P(B)\).
We then observe a heads in the \(k^{\text{th}}\) trial. We define the probability of this event is \(P(C)\).
Finally, the probability of observing \(m\) heads in the first \(k\) trials becomes \(P(B) \cdot P(C)\).
A random variable \(X\) is said to be a Pascal random variable with parameter \(m\) and \(p\), shown as \(X \sim Pascal(m,p)\), if its PMF is given by (\(0 < p < 1\))
Expectation and variance of \(X \sim Pascal (m,p)\):
import matplotlib.pyplot as plt
import numpy as np
from scripts.part2.basicFuncs import binCoeff
p = 0.3
m = 5
k = np.arange(50)
P_k = [binCoeff(n=i-1, k=m-1) * p**m * (1-p)**(i-m) for i in k]
fig = plt.figure(figsize=(4, 3), dpi=100)
ax = fig.add_subplot(111)
ax.plot(k, P_k, 'b.')
ax.vlines(
x=k,
ymin=np.zeros_like(k),
ymax=P_k,
colors='b',
)
ax.set(
title=r"$X \sim$" + " Pascal({:d}, {:.2f})".format(m, p),
xlim=[0, max(k)],
ylim=[0, 0.1],
)
plt.show()
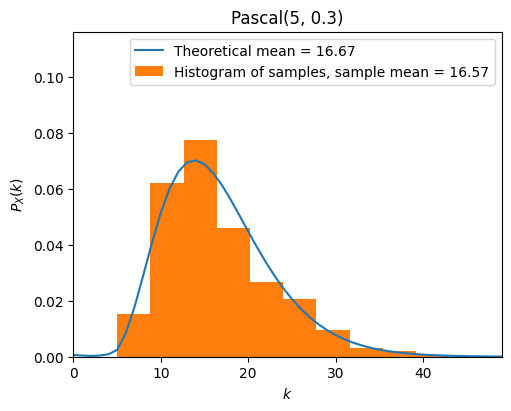
from scripts.part2.testFuncs import test5
test5(numTrials=500, m=5, p=0.3)
Poisson Distribution#
The Poisson distribution is one of the most widely used probability distributions. It is usually used in scenarios where we are counting the occurrences of certain events in an interval of time or space. Consider the following:
In a short time interval \(\Delta t\), the probability of an event occurring is proportional to \(\Delta t\), i.e., \(p = \lambda \Delta t\).
The probability of it happening more than twice in a short period of time is negligible.
In non-overlapping time periods, the number of times an event occurs is independent.
Let \(p\) represent the probability of an event occurring in a short time interval. Then the case of \(k\) events occuring in a certain time interval (we can regard it as \(n\) short time intervals, \(n \Delta t\)) follows the binomial distribution \(X \sim Binomial(n, p = \lambda \Delta t)\), where \(\lambda > 0\)
When \(n \to \infty\), for any \(k \in \{0, 1, 2, 3, ...\}\), we have
A random variable \(X\) is said to be a Poisson random variable with parameter \(\lambda\), shown as \(X \sim Poisson(\lambda)\), if its range is \(R_X = \{0, 1, 2, 3, ...\}\), and its PMF is given by
Expectation and variance of \(X \sim Poisson(\lambda)\):
import matplotlib.pyplot as plt
import numpy as np
from scripts.part2.basicFuncs import factI
lamb = 5
k = np.arange(20)
P_k = [np.exp(-lamb)*lamb**i / factI(i) for i in k]
fig = plt.figure(figsize=(4, 3), dpi=100)
ax = fig.add_subplot(111)
ax.plot(k, P_k, 'b.')
ax.vlines(
x=k,
ymin=np.zeros_like(k),
ymax=P_k,
colors='b',
)
ax.set(
title=r"$X \sim$" + " Poisson({:.2f})".format(lamb),
xlim=[0, max(k)],
ylim=[0, 0.2],
)
plt.show()
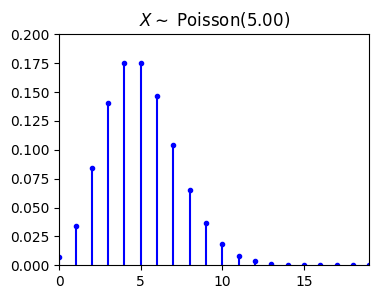
from scripts.part2.testFuncs import test6
test6(numTrials=1000, lamb=5)
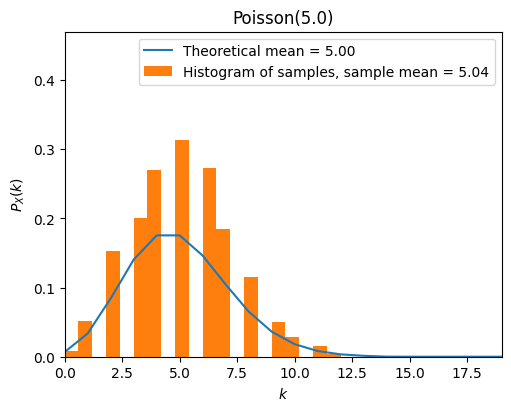
A Small Example of Poisson Distribution#
The number of customers that a Taiwanese fried chicken vendor has in Friday night can be modeled by a Poisson distribution with an average of 1.5 person per minute.
What is the probability that no customer visits this vendor in an interval of 10 minutes?
What is the probability that this vendor has more than 2 customers in an interval of 2 minutes?
Let \(X\) be the number of customer visits this vendor in an interval of 10 minutes. Then \(X\) is a Poisson random variable with parameter \(\lambda T = 1.5 \cdot 10 = 15\).
Let \(Y\) be the number of customer visits this vendor in an interval of 2 minutes. Then \(Y\) is a Poisson random variable with parameter \(\lambda T = 1.5 \cdot 2 = 3\).
import numpy as np
print(np.exp(-15)*15)
print(1 - np.exp(-3) - np.exp(-3)*3 - np.exp(-3)*9)
4.588534807527386e-06
0.3527681112177687
Uniform Distribution#
A continuous random variable \(X\) is said to be an Uniform random variable over the interval \([a, b]\), shown as \(X \sim Uniform(a, b)\), if its PDF is given by
Expectation and variance of \(X \sim Uniform(a, b)\):
from scripts.part2.testFuncs import test7
test7(numTrials=1000, a=-1, b=2)
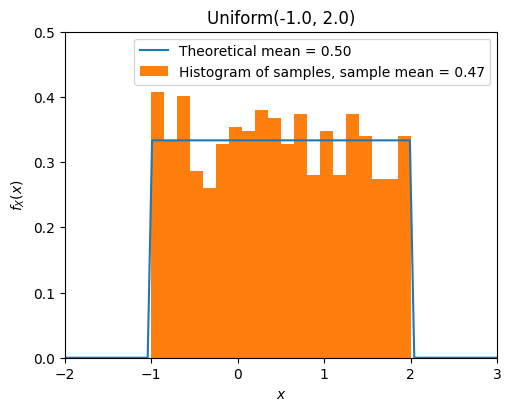
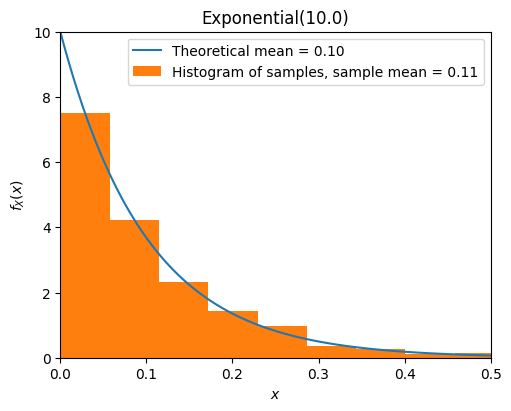
Exponential Distribution#
A continuous random variable \(X\) is said to be an exponential random variable with parameter \(\lambda > 0\), shown as \(X \sim Exponential(\lambda)\), if its PDF is given by
Expectation and variance of \(X \sim Exponential(\lambda)\):
from scripts.part2.testFuncs import test8
test8(numTrials=1000, lamb=10)
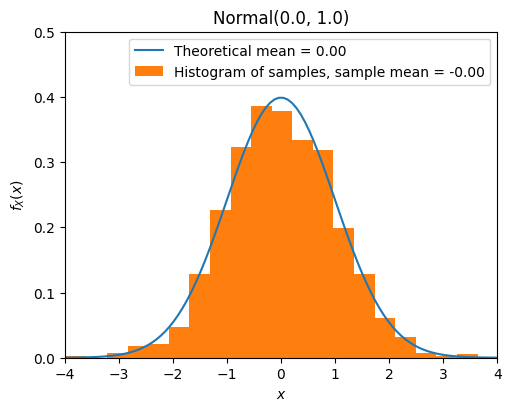
Normal Distribution (Gaussian)#
A continuous random variable \(X\) is said to be a normal random variable with parameter \(\mu\) and \(\sigma\), shown as \(X \sim N(\mu, \sigma)\), if its PDF is given by
Expectation and variance of \(X \sim Exponential(\lambda)\):
Special case: a continuous random variable \(Z\) is said to be a standard normal random variable, shown as \(Z \sim N(0, 1)\), if its PDF is given by
If \(X \sim N(\mu_X, \sigma_X^2)\), and \(Y = aX + b\), where \(a, b \in \mathbb{R}\), then
from scripts.part2.testFuncs import test9
test9(numTrials=1000, mu=0, sigma=1)
Gamma Distribution#
Gamma function#
The gamma function \(\Gamma(x)\) is an extension of the factorial function to real (and complex) numbers. If \(n \in \{1, 2, 3, ... \}\), then
For any positive real number \(\alpha\),
Using the change of variable \(x = \lambda y\), we can show the following equation that is often useful when working with the gamma distribution:
Also, using integration by parts it can be shown that
Properties of the gamma function#
For any positive real number \(\alpha\):
\(\Gamma(\alpha) = \int_0^{\infty} x^{\alpha - 1} e^{-x} \text{d}x.\)
\(\int_0^{\infty} x^{\alpha - 1} e^{- \lambda x} \text{d}x = \frac{\Gamma (\alpha)}{\lambda^{\alpha}}.\)
\(\Gamma(\alpha + 1) = \alpha \Gamma(\alpha).\)
\(\Gamma(n) = (n-1)!\), for \(n = 1, 2, 3, ...\).
\(\Gamma(\frac{1}{2}) = \sqrt{\pi}.\)
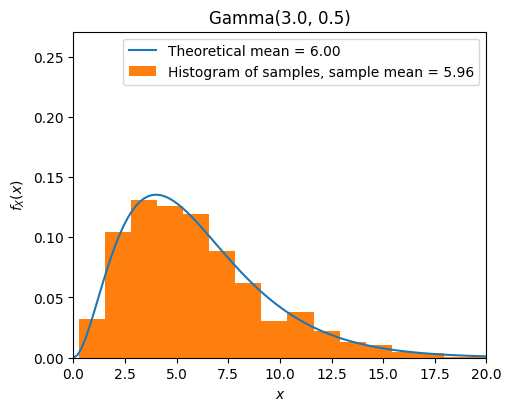
A continuous random variable \(X\) is said to be a gamma random variable with parameter \(\alpha > 0\) and \(\lambda > 0\), shown as \(X \sim Gamma(\alpha, \lambda)\), if its PDF is given by
Expectation and variance of \(X \sim Gamma(\alpha, \lambda)\):
from scripts.part2.testFuncs import test10
test10(numTrials=1000, alpha=3, lamb=1/2)
Summary of Mean and Variance#
Distribution |
Mean \(\big( \mu_X = \mathbb{E}[ X ] \big)\) |
Variance \(\big( Var(X) = \mathbb{E} [ (X - \mu_X)^2 ] \big)\) |
|---|---|---|
\(Bernoulli(p)\) |
\(p\) |
\(p \cdot (1-p)\) |
\(Geometric(p)\) |
\(\frac{1}{p}\) |
\(\frac{1-p}{p^2}\) |
\(Binomial(n, p)\) |
\(n \cdot p\) |
\(n \cdot p \cdot (1-p)\) |
\(Pascal(m, p)\) |
\(\frac{m}{p}\) |
\(\frac{m \cdot (1-p)}{p^2}\) |
\(Poisson(\lambda)\) |
\(\lambda\) |
\(\lambda\) |
\(Uniform(a, b)\) |
\(\frac{a+b}{2}\) |
\(\frac{(b-a)^2}{12}\) |
\(Exponential(\lambda)\) |
\(\frac{1}{\lambda}\) |
\(\frac{1}{\lambda^2}\) |
\(Normal(\mu, \sigma)\) |
\(\mu\) |
\(\sigma^2\) |
\(Gamma(\alpha, \lambda)\) |
\(\frac{\alpha}{\lambda}\) |
\(\frac{\alpha}{\lambda^2}\) |